- 首页 -- >>
微信矩阵-- >> 官微

-
夜思 | AlphaGo赢,正说明“人已胜天”!
发布时间:2017-05-25 08:22 来源:中青在线 作者:中国青年报官微

小年说:
柯洁以1/4子负于阿尔法狗(Alphago),这是中国围棋规则下,最小的胜负差。但在柯洁看来,Alphago已经接近围棋上帝。
很多人借此评判人与机器之高下,作者却认为,这一战不过是人脑与更先进的人脑的对决罢了。柯洁获胜,说明人类目前为止还是造物主最完美的作品;而AlphaGo胜,说明“人已胜天”!
推荐给你,静夜思。
AlphaGo赢,正说明“人已胜天”!
作者 | 小码哥 来源 | 有马体育 ID:youmatiyu
-01-
这一局柯洁输了,意料之中。
遥想去年年末12月29日,一个名叫Master的围棋人工智能横空出世,前后在弈城围棋和野狐围棋网站与各国世界顶尖级选手进行对弈,最后以60:0的压倒性战绩纷纷让棋士质疑人生,唯一一次平局也是因为Master对手意外断开网络连接。而这个所向披靡的Master其实就是AlphaGo新版本2.0。
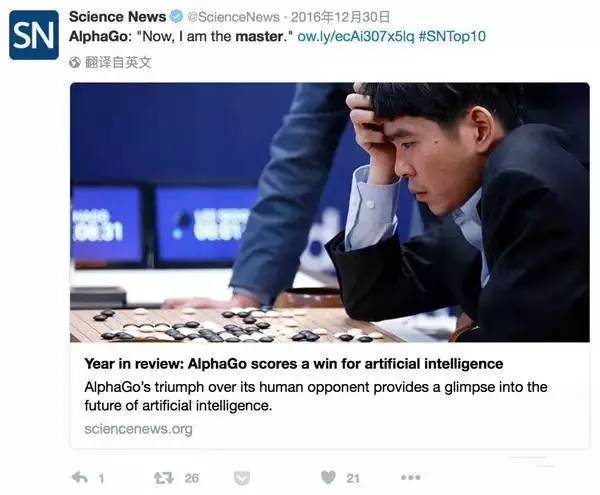
早在2016年3月,围棋人工智能AlphaGo就已经以4:1战胜过韩国第一围棋手李世石。比赛之前,李世石信心百倍,比赛之后,李世石说,他再也不想跟AlphaGo下棋了。有人开玩笑,“制服Master(AlphaGo)的唯一一个方法就是拔开电源”。哑然失笑,这个笑话的背后是对人工智能深深地恐惧。

然而,不要忘了,AlphaGo是出自人类之手。
去年年末战胜李世石以及一众围棋圣手的AlphaGo已经达到相当高的棋力,至少其计算能力和速度让人类望尘莫及。
去年的AlphaGo2.0,运用的神经网络系统模拟人脑的神经网络,已经不仅是一台超级计算机,而且是由许多个数据中心作为节点相连,每个节点内有多台超级计算机。一句话来概括就是,AlphaGo是集多种复杂的控制、算法为一体的人工智能。
-02-
围棋的复杂程度
AlphaGo最基本的系统是卷积神经网络 (Convolutional Neural Network, CNN)。由于围棋的规律可描述为“对弈双方在棋盘网格的交叉点上交替放置黑色和白色的棋子。落子完毕后,棋子不能移动。对弈过程中围地吃子,以所围‘地’的大小决定胜负。”而CNN则是用来识别图像。
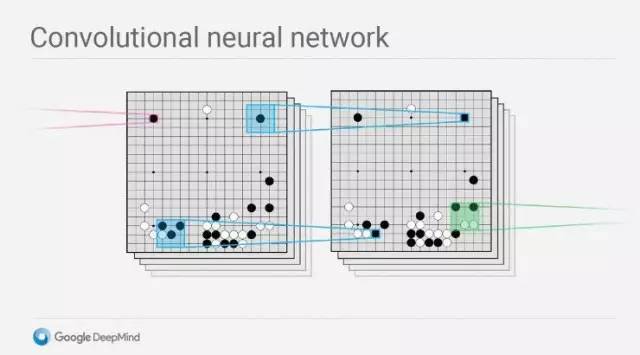
除了高效率识别的卷积神经网络,深度强化学习 (Deep Q-Learning, DQN)和蒙特卡洛树搜索算法 (Monte Carlo Tree Search)也是AlphaGo的核心算法。
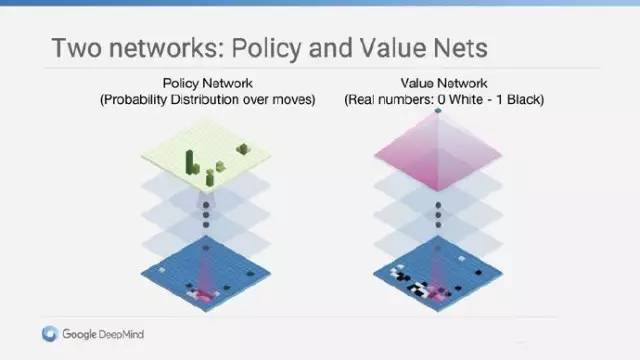
蒙特卡洛树搜索算法是一种人工智能问题中做出最优决策的方法,一般是在组合博弈中的行动(move)规划形式,它结合了随机模拟的一般性和树搜索的准确性。用人话来说就是,AlphaGo模拟自己与自己对弈,每一种落子都下到终局,在非常短的时间里穷尽所有情况,从而取得获胜概率。借助值网络(value network)与策略网络(policy network)这两种深度神经网络,通过值网络来评估大量选点,并通过策略网络选择落点。
所谓的深度强化学习就是指AlphaGo能够记住和学习3000万人类的棋谱,从而识别出与之对战的棋手的路数,其中包括了自主学习的能力,也就是每天自我对阵2000万局,以此获得所谓的“棋感”,以及在比赛中快速判断围棋的局势。这样一来就大大减少了树搜索的计算量。
AlphaGo自我对弈棋局
总而言之,横扫世界棋坛的AlphaGo2.0计算能力、大局观都超强,且不会受到丝毫人类棋士在对弈比赛中发生的心理、生理变化的影响,没有感性,只有理性到冷酷的算法和逻辑。
即使如此,AlphaGo也曾经在李世石的手中折过一局。那柯洁有可能赢吗?柯洁已经输了一局,想要在接下来的比赛中胜出,可能相当困难。
李世石与AlphaGo对弈第四局,AlphaGo出现漏洞
这一次,据说AlphaGo的棋力更增,可以做到在让前代AlphaGo四子的情况下仍然获胜,要知道,通常来讲让三子就已经达到代差级别。王小川认为,这一次的AlphaGo已经摆脱了监督学习,不再需要人类下围棋的历史数据,而是只通过“增强学习”和算法确定落子。王小川推测,此次AlphaGo可能已经放弃了监督学习,也就是说不再依赖原先人类的3000万局棋谱,甚至有可能放弃了蒙特卡洛树搜索,大大减少了暴力计算,落子速度更快、准确率更高。两台没有棋谱数据的AlphaGo自我对战学习如何下棋,并达到登峰造极的地步,只需要一周的时间。
如果说之前的AlphaGo还依赖于大量的数据、略有点笨重的计算,这是人工智能占据了硬件优势的地利,那么进化后的AlphaGo几乎就像是一个真正深谙围棋艺术的天才。

就在今年3月,人工智能在德州扑克领域也获得了全胜。加拿大阿尔伯塔大学计算机系的Matej Morav ík研发了一个被称为DeepStack的AI系统,它在每3000次无限德州扑克比赛后,具有统计意义地打败了11名职业扑克选手中的10名。相比于围棋,德州扑克的未知成分更多,在棋盘上棋手获得的是完全信息,但是在扑克游戏中每个玩家对可能的玩法有不对称的有限信息。这预示着AI在预测性上又一次进步。

-03-
人工智能一次又一次的进步,不禁让我们开始自我反省。即使AlphaGo打遍天下无敌手,围棋也只是人类智慧的一角,我们远不能说目前的人工智能超越了人类。
然而,我们应该反思,是否一直以来人类因为对自己的智慧认识不足而反过来产生盲目的迷信,断定人类思维具有不可及的高度,似乎这里有种本质的鸿沟横亘与人机之间。我可否将人对自己的盲目高估,理解为一种傲慢呢?
人与人工智能也许存在一种更积极的关系:通过AI让人类进一步地认识自己。
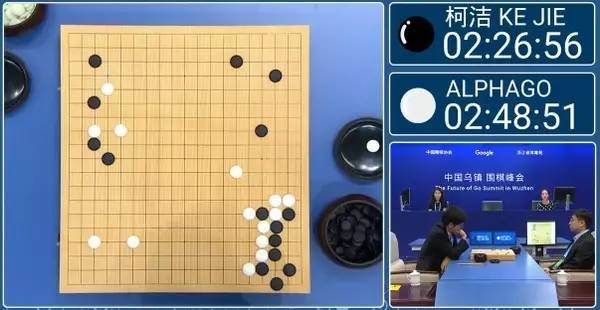
出征前,媒体们把此战称为“人机最后的决战”,柯洁说他抱着“必胜的态度,必死的决心”,大有一种肩负起全人类尊严的味道。 其实柯洁无需纠结,这一战不过是人脑与更先进的人脑的对决罢了。
柯洁获胜,说明人类目前为止还是造物主最完美的作品;而AlphaGo胜,说明“人已胜天”!
—THE END—
【责任编辑:郭艳丽】 - 热点新闻更多>>
-
- 习近平:努力建设一支强大的现代化海军
- 习近平致信祝贺全国台湾同胞投资企业联谊会成立10周年
- 习近平的全球观
- 李克强:后3年再改造各类棚户区1500万套
- 习近平:努力建设一支强大的现代化海军
- 习近平致信祝贺全国台湾同胞投资企业联谊会成立10周年
- 习近平鼓励抓好改革试点
- 总理力挺“互联网+”:中国数字经济已是“全球先驱”
- 习近平就曼彻斯特爆炸事件向英国女王致慰问电
- 习近平:认真谋划深入抓好各项改革试点
- 中国青年政治学院党委负责人答记者问
- 习近平主持召开中央全面深化改革领导小组第三十五次会议
- 习近平就曼彻斯特爆炸事件向英国女王致慰问电
- 《习近平谈治国理政》在海外圈粉无数
- 习近平为何强调“一带一路”建设要文明交流互鉴?
- 这杯“总理咖啡”与“中国制造2025”的化学反应
- 《互联网新闻信息服务许可管理实施细则》公布
- 这五年,习近平的扶贫足迹
- 习近平提共建“五路”有何深刻内涵?
- 经中央军委批准 《习近平论强军兴军》印发全军


















- 热图







- 青秀H5
-
-
习近平的“全球观”
 在“一带一路”国际合作高峰论坛上,习近平为全球问题把脉,那么他的“全球观”如何呢?
在“一带一路”国际合作高峰论坛上,习近平为全球问题把脉,那么他的“全球观”如何呢? -
优秀团员养成记
 入团宣誓、创新型团课、志愿服务……点进来,教你成为一名优秀的共青团员!
入团宣誓、创新型团课、志愿服务……点进来,教你成为一名优秀的共青团员! -
教你拍出独具创意的毕业照
 毕业季,不留点创意照片怎么行!那么,如何才能让自己的毕业照别具一格?
毕业季,不留点创意照片怎么行!那么,如何才能让自己的毕业照别具一格?
-
- 新闻排行榜
- 网评